
2021/01/22 - [IT/R] - R언어 공부 정리 [6]
2021/01/21 - [IT/R] - R언어 공부 정리 [5]
2021/01/20 - [IT/R] - R언어 공부 정리 [4]
2021/01/19 - [IT/R] - R 언어 공부 정리 [3]
2021/01/18 - [IT/R] - R 언어 공부정리 [2]
2021/01/15 - [IT/R] - 분석 , 통계시 유용한 R 언어 설치와 기본 공부 정리
이번엔 지금까지 공부했던 내용을 가지고 분석 프로젝트를 해보겠습니다.
github.com/youngwoos/Doit_R/tree/master/Data
youngwoos/Doit_R
저장소. Contribute to youngwoos/Doit_R development by creating an account on GitHub.
github.com
위의 링크에서 Koweps_hpc10_2015_beta1.sav 파일을 다운받아 준비를 합니다.
1. 필요한 패키지 설치와 로드
<go />
install.packages('foreign') # foreign 패키지 설치
foreign 패키지는 SPSS 파일로드, SAS , STATA 통계 소프트웨어 파일을 사용할수 있습니다.
분석을 위해 사용되는 나머지 패키지를 로드하겠습니다.
<go />library(foreign) # spss 파일 로드 library(dplyr) # 전처리 library(ggplot2) # 시각화 library(readxl) # 엑셀파일 불러올때
spss 파일을 데이터 프레임으로 불러와서 사용할수 있게 합니다.
<go />
raw_welfare <- read.spss(file='Koweps_hpc10_2015_beta1.sav',
to.data.frame = T)
원본은 두고 복사본을 만들어서 사용하겟습니다.
<go />welfare <- raw_welfare
기본적으로 몇행 몇열인지 무슨 데이터가 들어가있는지 컬럼은 데이터형이 무엇인지 등등을 알아보도록 합니다.
<go />
dim(welfare) # 16664 957
head(welfare)
tail(welfare)
str(welfare)
summary(welfare)

데이터를 보면 957열 이므로 원하는 컬럼을 찾기가 어렵습니다 저희가 알아볼수 있게 변수명을 바꾸도록 하겠습니다.
<go />welfare <- rename(welfare, sex=h10_g3, # 성별 birth=h10_g4, # 태어난 연도 marriage=h10_g10, # 혼인 상태 religion=h10_g11, # 종교 income=p1002_8aq1, # 월급 code_job=h10_eco9, # 직종 코드 code_region=h10_reg7 # 지역코드 )
1.1. 성별 전처리
우선 성별 변수 데이터형과 이상치가 존재하는지 확인합니다.
<go />
class(welfare$sex) # 데이터형 확인
[1] "numeric"
table(welfare$sex) # 이상치 확인
1 2
7578 9086
확인 결과 이상치는 존재하지않습니다.
근데 만약 이상치가 존재한다면 NA로 수정해주고 결측치 NA를 없애거나 다른수로 나타내야됩니다.
<go />welfare$sex <- ifelse(welfare$sex==이상치,NA,welfare$sex)
결측치가 존재하는지 확인
<go />
table(is.na(welfare$sex))
# 결측치 존재 유무
FALSE
16664
이번에는 알아보기 쉽게 성별 1을 male로 2를 female로 수정해줍니다.
<go />
welfare$sex <- ifelse(welfare$sex==1,"male",'female')
# 수정후 확인
table(welfare$sex)
# 실행 결과
female male
9086 7578
성별 전처리가 끝났으니 월급 전처리를 합니다 : 이상치와 결측치가 있다면 제거합니다.
<go />
class(welfare$income)
# [1] "numeric"
table(is.na(welfare$income))
# 결과
FALSE TRUE
4634 12030
TRUE가 12030개로 결측치가 엄청 많음
<go />
boxplot(welfare$income)
boxplot(welfare$income)$stats
[,1]
[1,] 0.0
[2,] 122.0
[3,] 192.5
[4,] 316.6
[5,] 608.0
boxplot으로 확인결과 이상치(극단치)가 많은것을 볼수있습니다.
0보다 작거나 608보다 크면 이상치 입니다.
이상치(극단치)를 모두 결측치 NA 로 바꿔줍니다.
<go />
welfare$income <- ifelse(welfare$income<0 | welfare$income >608, NA , welfare$income )
성별에 따른 월급차이가 있는지 분석해 봅시다.
<go />
wf <- welfare %>% filter(!is.na(sex) & !is.na(income)) %>%
group_by(sex) %>% summarise(income_avg=mean(income))
filter로 성별과 수입이 결측치 인것을 제외하고
성별기준 월급의 평균을 알아봅니다.
# A tibble: 2 x 2
sex income_avg
<chr> <dbl>
1 female 156.
2 male 272.
눈으로 확인하기 위해 시각화를 해줍니다 .
이제 나이와 월급간의 관계를 알아봅시다. 몇살때 가장 월급을 많이 받을까?
우선 출생년도를 기준으로 나이를 구해야 합니다.
우선 이상치가 있는지 확인해봅니다.
<go />
boxplot(welfare$birth)
# 이상치(극단치) 존재하지않음
table(is.na(welfare$birth))
# 결측치 확인 결과 존재하지않음
FALSE
16664
만약 이상치가 있을경우 결측 처리 합니다.
<go />welfare$birth <- ifelse(welfare$birth==이상치,NA,welfare$birth)
나이 변수를 만들고 데이터 기준 2015년 이므로 2015년 - 출생년도 +1 을 해줍니다
그리고 데이터를 확인해봅니다
<go />
welfare$age <- 2015-welfare$birth +1 # 나이변수
summary(welfare$age)
summary(welfare$age)
Min. 1st Qu. Median Mean 3rd Qu. Max.
2.00 28.00 50.00 48.43 70.00 109.00
qplot(welfare$age)
나이에 따른 월급 평균표를 구해봅시다
<go />age_income <- welfare %>% # welfare 데이터에서 filter(!is.na(income)) %>% # income 결측치 제외 group_by(age) %>% # 나이 별 summarise(mean_income=mean(income)) # 월급 평균
눈으로 보기위한 선형 그래프를 생성해줍니다.
연령대에 따른 월급의 차이를 알고싶습니다. 30대 미만은 young , 30~60 middle , 60 이상은 old 컬럼을 추가해봅시다
<go />
wf2 <- welfare %>% mutate(agegroup = ifelse(age<30,'young',ifelse(age<=59,'middle','old')))
# 새 컬럼 agegroup을 추가해서 30대 미만은 young
# 60세 미만은 middle 그 이상은 old
<go />
table(wf2$agegroup) # 빈도를 측정해봅시다
middle old young
6049 6281 4334
# 빈도를 나타내 봅시다
qplot(wf2$agegroup)
이제 새로운 데이터프레임에 연령대별 월급평균을 구해봅시다.
<go />agegroup_income <- wf2 %>% # wf2 데이터에서 filter(!is.na(income)) %>% # 월급이 결측치가 아닌것 group_by(agegroup) %>% # 나이대별 summarise(mean_income=mean(income)) # 월급 평균
막대 그래프로 나타내 봅시다.
<go />ggplot(data=agegroup_income,aes(x=agegroup,y=mean_income)) + geom_col()
그래프 표시할때 알파벳순서로 컬럼이 표시되는데 이 컬럼순서를 변경하기 위해선 scale_x_discrete(limits=()) 를 사용합니다. young , middle , old 순서대로 표시해 보겠습니다.
<go />
ggplot(data=agegroup_income,aes(x=agegroup,y=mean_income)) + geom_col()+
scale_x_discrete(limits=c("young","middle","old"))
1.2. 연령대 및 성별 월급차이를 분석해봅시다
연령대에서 성별에 따른 월급차이가 있는지 알아보기 위해 연령대 및 성별에 따른 월급 평균표를 만들어봅시다.
<go />
sex_income <- wf2 %>% # welfare 데이터를
filter(!is.na(income)) %>% #월급 결측치를 제외하고
group_by(agegroup,sex) %>% #연령대 별 성 별
summarise(mean_income = mean(income)) # 월급평균
# A tibble: 6 x 3
# Groups: agegroup [3]
agegroup sex mean_income
<chr> <chr> <dbl>
1 middle female 186.
2 middle male 353.
3 old female 81.5
4 old male 174.
5 young female 160.
6 young male 171.
앞에서 만든 표를 이용해서 그래프를 생성해봅시다.
막대는 연령대별로 표현되도록 x축에는 agegroup을 지정
또 막대가 성별에 따라 다른색이 표현되도록 fill에 sex를 지정하고 축 순서는 연령대 순서대로 설정해봅시다.
<go />
ggplot(data=sex_income,aes(x=agegroup,y=mean_income,fill=sex))+
geom_col()+ # 막대 그래프 y축이 값
scale_x_discrete(limits = c("young","middle","old")) # 정렬
위와 같이 출력하면 성별의 월급이 막대에 한번에 표현되어 차이를 비교하기 힘든데
geom_col()의 position='dodge'로 설정해서 막대를 분리해줍니다.
<go />
ggplot(data=sex_income,aes(x=agegroup,y=mean_income,fill=sex))+
geom_col(position="dodge")+
scale_x_discrete(limits = c("young","middle","old"))
이번엔 연령대말고 나이와 성별 월급평균을 그래프로 만들어보겠습니다.
선그래프에 성별에 따라 다르게 표현되도록 만들어봅시다.
우선 성별 연령별 월급 평균표를 생성해줍니다.
<go />
sex_age <- wf2 %>% # wf2 데이터에서
filter(!is.na(income)) %>% # 월급 결측치 제외
group_by(age,sex) %>% #나이별 성별
summarise(mean_income=mean(income)) # 월급 평균
age sex mean_income
<dbl> <chr> <dbl>
1 20 female 147.
2 20 male 69
3 21 female 107.
4 21 male 102.
5 22 female 140.
6 22 male 118.
7 23 female 139.
8 23 male 153.
9 24 female 126.
10 24 male 158.
# ... with 124 more rows
그래프로 만들어줍시다.
선형은 aes 파라미터가 col 이 들어와야되고 막대는 fill 입니다
<go />ggplot(data=sex_age,aes(x=age,y=mean_income,col=sex))+geom_line()
1.3. 직업별 월급 차이 분석
어떤 직업이 월급을 많이 받는지 분석해보겠습니다.
먼저 welfare에 있는 code_job 은 직업변수입니다.
<go />
class(welfare$code_job)
# [1] "numeric"
<go />table(welfare$code_job)
<go />
111 120 131 132 133 134 135 139 141 149 151 152 153 159 211 212 213
2 16 10 11 9 3 7 10 35 20 26 18 15 16 8 4 3
221 222 223 224 231 232 233 234 235 236 237 239 241 242 243 244 245
17 31 12 4 41 5 3 6 48 14 2 29 12 4 63 4 33
246 247 248 251 252 253 254 259 261 271 272 273 274 281 283 284 285
59 77 38 14 111 24 67 109 4 15 11 4 36 17 8 10 26
286 289 311 312 313 314 320 330 391 392 399 411 412 421 422 423 429
16 5 140 260 220 84 75 15 4 13 87 47 12 124 71 5 14
431 432 441 442 510 521 522 530 611 612 613 620 630 710 721 722 730
20 33 154 197 192 353 5 106 1320 11 40 2 20 29 30 22 16
741 742 743 751 752 753 761 762 771 772 773 774 780 791 792 799 811
27 3 34 34 5 49 69 27 11 61 86 7 17 5 21 45 16
812 819 821 822 823 831 832 841 842 843 851 852 853 854 855 861 862
1 6 9 9 23 5 17 32 10 4 19 13 7 33 9 3 14
863 864 871 873 874 875 876 881 882 891 892 899 910 921 922 930 941
17 31 2 257 34 37 2 2 3 8 19 16 102 31 74 289 325
942 951 952 953 991 992 999 1011 1012
99 125 122 73 45 12 141 2 17
직업 변수에는 직업 코드로 분류 되어있어서 무슨 직업인지 알수없으므로 직업 분류코드를 이용해 직업 명칭을 만들어줘야 합니다.
글 상단에 있는 깃허브 링크에서 Koweps_Codebook.xlsx 를 다운받아서 불러옵니다.
엑셀 시트 두번째에 직종코드 시트가 직업분류 코드입니다.
엑셀 파일을 불러와야 하므로 readxl 패키지를 부르고 첫행에 컬럼명이 존재하므로 col_names를 추가해줍니다
<go />
library(readxl)
list_job <- read_excel("Koweps_Codebook.xlsx",col_names = T,sheet = 2)
head(list_job)
# A tibble: 6 x 2
code_job job
<dbl> <chr>
1 111 의회의원 고위공무원 및 공공단체임원
2 112 기업고위임원
3 120 행정 및 경영지원 관리자
4 131 연구 교육 및 법률 관련 관리자
5 132 보험 및 금융 관리자
6 133 보건 및 사회복지 관련 관리자
left_join()으로 job 변수를 welfare 데이터와 결합하는데 공통으로 들어있는 code_job 변수를 기준으로 하면됩니다.
<go />
welfare <- left_join(welfare,list_job,id="code_job")
# 확인 작업
welfare %>% filter(!is.na(code_job)) %>%
select(code_job,job) %>% head(5)
#실행 결과
code_job job
1 942 경비원 및 검표원
2 762 전기공
3 530 방문 노점 및 통신 판매 관련 종사자
4 999 기타 서비스관련 단순 종사원
5 312 경영관련 사무원
이번에 직업별 월급 차이를 분석해 보겠습니다 .
우선 직업별 월급의 평균을 구합니다.
<go />
job_income <- welfare %>% filter(!is.na(job) & !is.na(income)) %>% # 직업이 없는경우 월급이 없는경우 제외
group_by(job) %>% #직업별
summarise(mean_income = mean(income)) # 월급 평균
# A tibble: 142 x 2
job mean_income
<chr> <dbl>
1 가사 및 육아 도우미 80.2
2 간호사 241.
3 건설 및 광업 단순 종사원 190.
4 건설 및 채굴 기계운전원 358.
5 건설 전기 및 생산 관련 관리자 536.
6 건설관련 기능 종사자 247.
7 건설구조관련 기능 종사자 242.
8 건축 및 토목 공학 기술자 및 시험원 378.
9 건축마감관련 기능 종사자 254.
10 경비원 및 검표원 134.
# ... with 132 more rows
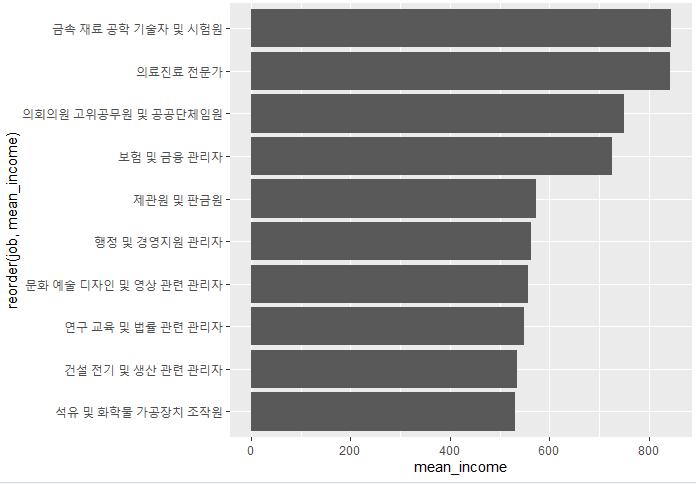
어떤 직업이 월급이 많은지 알아보기 위해 내림차순으로 상위 10개를 확인하겠습니다.
<go />
job_income_desc <- job_income %>%
arrange(desc(mean_income)) %>%
head(10)
# A tibble: 10 x 2
job mean_income
<chr> <dbl>
1 금속 재료 공학 기술자 및 시험원 845.
2 의료진료 전문가 844.
3 의회의원 고위공무원 및 공공단체임원 750
4 보험 및 금융 관리자 726.
5 제관원 및 판금원 572.
6 행정 및 경영지원 관리자 564.
7 문화 예술 디자인 및 영상 관련 관리자 557.
8 연구 교육 및 법률 관련 관리자 550.
9 건설 전기 및 생산 관련 관리자 536.
10 석유 및 화학물 가공장치 조작원 532.
이제 위에서 만든 표를 가지고 그래프를 생성해줍니다. x축에 직업이름이 길어서 기본적으로 생성하게되면
이름이 겹치게 되서 보기 힘듭니다. coord_flip()을 추가해서 90도를 회전해줍니다.
<go />ggplot(data=job_income_desc,aes(x=reorder(job,mean_income),y=mean_income))+ geom_col()+coord_flip()
이번에는 하위도 확인해 보겠습니다.
<go />
job_income_asc <- job_income %>%
arrange(mean_income) %>%
head(10)
# A tibble: 10 x 2
job mean_income
<chr> <dbl>
1 가사 및 육아 도우미 80.2
2 임업관련 종사자 83.3
3 기타 서비스관련 단순 종사원 88.2
4 청소원 및 환경 미화원 88.8
5 약사 및 한약사 89
6 작물재배 종사자 92
7 농립어업관련 단순 종사원 102.
8 의료 복지 관련 서비스 종사자 104.
9 음식관련 단순 종사원 108.
10 판매관련 단순 종사원 117.
마찬가지로 그래프로 확인해줍니다
<go />ggplot(data=job_income_asc,aes(x=reorder(job,-mean_income),y=mean_income))+ geom_col()+coord_flip()
그래프 생성시 한가지 헷갈릴수 있는데 데이터가 정렬되어있어도 그래프는 정렬이 되어있지 않습니다.
그러므로 그래프 생성시 정렬 옵션 reorder() 를 해주어야합니다.
1.4. 성별 직업 빈도 구하기
성별,직업 변수 전처리 작업은 위에서 완료했으므로 변수간의 관계를 분석합니다.
성별 월급 평균표와 그래프 만들기 작업
남성의 직업 빈도를 구해 가장 높은것 10개 추출후에 그래프를 작성해보겠습니다.
<java />
job_male <- welfare %>% # welfare 데이터에서
filter(!is.na(job)& sex == "male") %>% #직업에 결측치가 아닌것과 남성인것
group_by(job) %>% # 직업별
summarise(n=n()) %>% #개수
arrange(desc(n)) %>% # 내림차순
head(10)
# A tibble: 10 x 2
job n
<chr> <int>
1 작물재배 종사자 640
2 자동차 운전원 251
3 경영관련 사무원 213
4 영업 종사자 141
5 매장 판매 종사자 132
6 제조관련 단순 종사원 104
7 청소원 및 환경 미화원 97
8 건설 및 광업 단순 종사원 95
9 경비원 및 검표원 95
10 행정 사무원 92
그래프 작업
<java />ggplot(data=job_male,aes(x=reorder(job,n),y=n)) + geom_col()+ coord_flip()
geom_col()과 geom_bar() 는 아직도 헷갈린다. 아래의 링크를 참고해보자..
R08_ggplot2를 이용한 여러가지 그래프
Goals geom_col( ), reorder, xlab, ylab, geom_bar ggplot2 : cheat sheet, geom_col vs geom_bar 빈도수 순서로 출력 선 그래프, boxplot , 하나의 차트에서 여러 개의 boxplot 만들기 ggthemes #ggplot2.tidyv..
morningcoding.tistory.com
이번엔 여성의 직업 빈도를 구해봅시다. 남성에서 약간만 수정해주면 됩니다.
<java />
job_female <- welfare %>% # welfare 데이터에서
filter(!is.na(job)& sex == "female") %>% #직업에 결측치가 아닌것과 남성인것
group_by(job) %>% # 직업별
summarise(n=n()) %>% #개수
arrange(desc(n)) %>% # 내림차순
head(10)
job n
<chr> <int>
1 작물재배 종사자 680
2 청소원 및 환경 미화원 228
3 매장 판매 종사자 221
4 제조관련 단순 종사원 185
5 회계 및 경리 사무원 176
6 음식서비스 종사자 149
7 주방장 및 조리사 126
8 가사 및 육아 도우미 125
9 의료 복지 관련 서비스 종사자 121
10 음식관련 단순 종사원 104
그래프 작업
<java />ggplot(data=job_female,aes(x=reorder(job,n),y=n)) + geom_col()+ coord_flip()
1.5. 종교 유무에 따른 이혼율을 분석해 봅시다
가정으로 종교가 있는 사람들이 이혼을 덜 하는지 세워봅시다
먼저 종교 변수와 혼인상태의 검토와 전처리를 해줍니다.
<java />
class(welfare$religion)
# [1] "numeric"
table(welfare$religion)
# 1 2
# 8047 8617
종교 유무가 1 2 로 구분되어 있고 결측치는 없는거같습니다 .
종교 유무에 따라 문자를 부여해줍니다 종교가있는 8047명은 yes 종교가 없는 8617명은 no
<java />
# 종교 유무에 이름 부여함
welfare$religion <- ifelse(welfare$religion==1,'yes','no')
table(welfare$religion)
# no yes
# 8617 8047
qplot(welfare$religion)
혼인 상태 변수의 검토와 전처리를 해줍니다.
<java />
class(welfare$marriage)
# [1] "numeric"
table(welfare$marriage)
# 0 1 2 3 4 5 6
# 2861 8431 2117 712 84 2433 26
혼인상태 변수에 대한 정보는 배우자 있으면 1 , 이혼시 3 그 외에는 NA 처리하겠습니다.
<java />
# 이혼 여부 변수
welfare$group_marriage <- ifelse(welfare$marriage==1,'marriage',
ifelse(welfare$marriage==3,'disvorce',NA))
table(welfare$group_marriage)
# disvorce marriage
# 712 8431
#
<java />
table(is.na(welfare$marriage))
# FALSE TRUE NA 데이터 7521개
# 9143 7521
# 둘중 어디에도 속하지 않는 결측치 7521개
1.6. 종교 유무에 따른 이혼률 표를 만들어봅시다
경우의 수는 총 4가지가 나옵니다. [종교 O/X , 결혼 O/X ] 2가지 * 2가지 총 4가지 입니다
먼저 종교유무와 결혼상태별로 나눠서 빈도를 구하고 각 종교 유무집단의 빈도로 나눠서 비율을 구합니다.
<java />
welfare %>% filter(!is.na(group_marriage)) %>% # 결측치 제외
group_by(religion,group_marriage) %>% # 종교유무,결혼유무
summarise(n=n()) %>% # 종교유무/이혼유무 / 즉 4종류를 카운트합니다
mutate(tot_group=sum(n)) %>% # 합은 첫번째 조건 종교 유무 2종류 sum합산을 한다
mutate(pct =round(n/tot_group*100,1)) # 소수점 첫째 자리까지
# Groups: religion [2]
religion group_marriage n tot_group pct
<chr> <chr> <int> <int> <dbl>
1 no disvorce 384 4602 8.3
2 no marriage 4218 4602 91.7
3 yes disvorce 328 4541 7.2
4 yes marriage 4213 4541 92.8
dplyr()의 count() 는 집단별 빈도를 구하는 함수입니다. count() 를 이용하고 비율을 구하는 mutate()를 하나로 합치면 아래와 같이 쓸수있습니다.
<java />
religion_marriage <- welfare %>%
filter(!is.na(group_marriage)) %>%
count(religion, group_marriage) %>%
group_by(religion) %>%
mutate(pct = round(n/sum(n)*100, 1))
Groups: religion [2]
religion group_marriage n pct
<chr> <chr> <int> <dbl>
1 no disvorce 384 8.3
2 no marriage 4218 91.7
3 yes disvorce 328 7.2
4 yes marriage 4213 92.8
앞에서 생성한 표에서 이혼에 해당하는 값을 가져와서 이혼율 표를 만듭니다.
<java />
r_divorce <- r_marriage %>%
filter(group_marriage=="divorce") %>%
select(religion,pct)
r_divorce
religion pct
<chr> <dbl>
1 no 8.3
2 yes 7.2
그래프를 생성해 줍니다.
<java />ggplot(data = r_divorce,aes(x=religion,y=pct)) + geom_col() # geom_col() 값
'IT 기술 > R' 카테고리의 다른 글
| R언어 공부정리 [8] (0) | 2021.01.27 |
|---|---|
| 데이터 마이닝 R 4버전 이상 - KoNLP 설치 (0) | 2021.01.26 |
| R언어 공부 정리 [6] (0) | 2021.01.22 |
| R언어 공부 정리 [5] (0) | 2021.01.21 |
| R언어 공부 정리 [4] (2) | 2021.01.20 |
