
데이터를 분석할때는 다양한 명령어가 존재합니다.
확인 하기전에 저번 포스팅에 올렸던 깃허브에 있는 csv_exam.csv 파일을 준비해야합니다.
2021/01/18 - [IT/R] - R 언어 공부정리 [2]
<go />
exam <- read.csv('csv_exam.csv')
exam
head(exam) : 상단에서 6행을 출력합니다.
만약 뒤에 head(exam,10) 이런식으로 붙는다면 10행까지 출력됩니다.
<go />
id class math english science
1 1 1 50 98 50
2 2 1 60 97 60
3 3 1 45 86 78
4 4 1 30 98 58
5 5 2 25 80 65
6 6 2 50 89 98
tail(exam) : 하단에서 6행 출력을 출력합니다.
<go />
id class math english science
15 15 4 75 56 78
16 16 4 58 98 65
17 17 5 65 68 98
18 18 5 80 78 90
19 19 5 89 68 87
20 20 5 78 83 58
View(exam) : 데이터 뷰어 창을 열어 데이터를 확인합니다.

dim(exam) : 데이터의 행,열이 몇행 몇열인지 알수 있다.
<go />
> dim(exam) # 행 열
[1] 20 5
str(exam) : 모든컬럼의 데이터형을 출력한다.
<go />
'data.frame': 20 obs. of 5 variables:
$ id : int 1 2 3 4 5 6 7 8 9 10 ...
$ class : int 1 1 1 1 2 2 2 2 3 3 ...
$ math : int 50 60 45 30 25 50 80 90 20 50 ...
$ english: int 98 97 86 98 80 89 90 78 98 98 ...
$ science: int 50 60 78 58 65 98 45 25 15 45 ...
summary(exam) : 데이터프레임을 요약 통계를 출력한다.
<go />
> summary(exam)
id class math english science
Min. : 1.00 Min. :1 Min. :20.00 Min. :56.0 Min. :12.00
1st Qu.: 5.75 1st Qu.:2 1st Qu.:45.75 1st Qu.:78.0 1st Qu.:45.00
Median :10.50 Median :3 Median :54.00 Median :86.5 Median :62.50
Mean :10.50 Mean :3 Mean :57.45 Mean :84.9 Mean :59.45
3rd Qu.:15.25 3rd Qu.:4 3rd Qu.:75.75 3rd Qu.:98.0 3rd Qu.:78.00
Max. :20.00 Max. :5 Max. :90.00 Max. :98.0 Max. :98.00
Min : 최하위 값
1st Qu. 하위 25% 기준값
Median : 중간값
Mean : 평균값
3dr Qu : 상위 25% 기준값
Max : 최대 값
1. 변수명 바꾸기
테스트를 위한 데이터 프레임을 하나 생성해 줍니다.
<go />
df_row <- data.frame(var=c(1,2,1), var2=c(2,3,2))
df_row
# === 실행결과 ===
var var2
1 1 2
2 2 3
3 1 2
dplyr 패키지는 분석할때 가장 많이 사용하는 패키지 입니다 .
<go />
install.packages('dplyr')
library(dplyr)
패키지 설치후에 라이브러리 로드를 해줍니다.
rename(데이터프레임,바꿀변수명=원래변수명,,,)
<go />
df_row <- rename(df_row,v1=var,v2=var2)
df_row
# ==== 실행결과 ===
v1 v2
1 1 2
2 2 3
3 1 2
새로운 컬럼을 추가하기
df_row 데이터프레임에 있는 $v1 값과 $v2 값을 가져와서 더하고 sum 에 집어넣는다.
<go />
> df_row$sum <- df_row$v1 + df_row$v2
> df_row
# === 실행결과 ===
v1 v2 sum
1 1 2 3
2 2 3 5
3 1 2 3
평균값을 구하고 싶다면
<go />
df_row$avg <- df_row$sum/2
df_row
# 실행결과
v1 v2 sum avg
1 1 2 3 1.5
2 2 3 5 2.5
3 1 2 3 1.5
이제 기본예제에 있는 mpg 데이터를 분석해 봅시다.
고속도로 연비와 도시연비의 합과 평균을 구하고 새로운 컬럼 total과 avg를 추가
<go />
mpg$total <- (mpg$cty+mpg$hwy)
mpg$total_avg <- mpg$total/2
제대로 값이 들어갔는지 head()를 통해 확인
<go />
manufacturer model displ year cyl trans drv cty hwy fl class total total_avg
1 audi a4 1.8 1999 4 auto(l5) f 18 29 p compact 47 23.5
2 audi a4 1.8 1999 4 manual(m5) f 21 29 p compact 50 25.0
3 audi a4 2.0 2008 4 manual(m6) f 20 31 p compact 51 25.5
4 audi a4 2.0 2008 4 auto(av) f 21 30 p compact 51 25.5
5 audi a4 2.8 1999 6 auto(l5) f 16 26 p compact 42 21.0
6 audi a4 2.8 1999 6 manual(m5) f 18 26 p compact 44 22.0
통합연비의 평균은 ?
<go />mean(mpg$total_avg)
total 과 total_avg의 요약 통계는 ?
<go />summary(mpg$total) summary(mpg$total_avg)
2. 데이터 분포도 : 데이터가 분포되어 있는 정도를 표시해줍니다. [히스토그램]
<go />hist(mpg$total) hist(mpg$hwy) hist(mpg$cty)
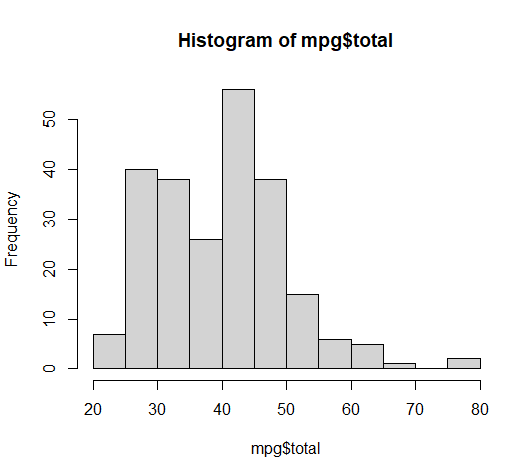
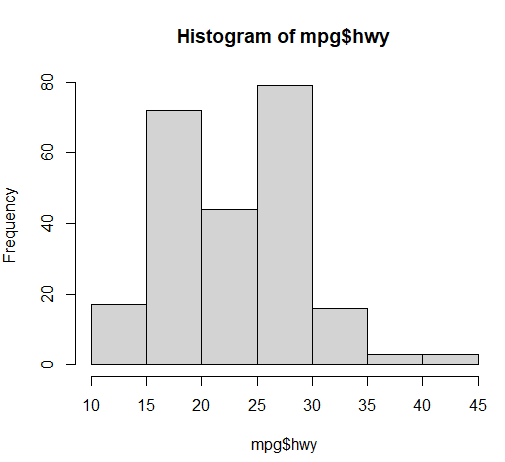
mpg$total_avg (평균 연비가 20 이상이면 pass , 아니면 fail을 나타내는 컬럼 check 추가하기
<go />
mpg$check <- ifelse(mpg$total_avg >=20,"pass",'fail')
이때 mpg$check로 확인을 하게되면 어떤값이 더 많은지 무슨값이 있는지 보기가 어렵다
이럴때는 눈으로 보기쉽게 qplot(mpg$check) 혹은
수치로 정확히 알고싶으면 table(mpg$check) 이렇게 사용하면 된다.
<go />
> table(mpg$check)
fail pass
106 128
table(mpg$check) 사용시 fail 이 몇개 pass가 몇개인지 정확히 알수있다.
table은 빈도 테이블로 특정 데이터가 몇개 있는지 나타내는 표 이다.
중첩 조건문
ifelse(조건식,'참값',ifelse(조건식,'참값','거짓값'))
조건식을 판별해서 만약 거짓값이 나온다면 한번도 조건을 판별해서 나타낸다.
예를 들어 통합연비 평균이 (mpg$total_avg) 30이상이면 A , 20이상이면 B , 그 외에는 C 등급을 부여하는 컬럼을 만든다고 하면 아래와 같이 작성하면 된다.
<go />
mpg$grade <- ifelse(mpg$total_avg >= 30 , 'A',ifelse(mpg$total_avg >= 20,'B','C'))
빈도 테이블로 확인해보자
A가 제일 적고 B가 가 제일 많고 c 가 중간이라는것을 알수있다.
정확히 몇개 있는지 보려면 table(mpg$grade)를 사용하자
<go />
A B C
10 118 106
이번엔 ggplot2에 들어있는 midwest로 분석을 해보자
우선 ggplot2의 midwest 데이터를 프레임 형태로 불러온다
<go />midwest <- as.data.frame(ggplot2::midwest)
dim(midwest) 를 통해 몇개의 행과 몇개의 열이 있는지 확인한다
poptotal 변수를 total로 , popasian 변수를 asian으로 수정을 해줍니다.
<go />midwest <- rename(midwest,total=poptotal) midwest <- rename(midwest,asian=popasian)
전체인구(total), 아시아인구(asian)을 이용해서 인구백분율을 나타내는 파생변수 asianrate을 추가하고
히스토그램을 작성하시오.
<go />
midwest$asianrate <- (midwest$asian/midwest$total) * 100
hist(midwest$asianrate)
아시아 인구 백분율의 전체 평균을 구해서 , 만약 평균을 초과하면 large , 아니면 small을 부여하는 변수 size를 만들자.
<go />
midwest$size <- ifelse(midwest$asianrate > mean(midwest$asianrate),'large','small')
large 와 small 이 해당하는 지역이 얼마나 되는지 빈도표와 빈도 그래프를 작성하자
빈도 표
<go />
table(midwest$size)
# 실행 결과
large small
119 318
빈도 그래프
<go />qplot(midwest$size)
'IT 기술 > R' 카테고리의 다른 글
| R언어 공부 정리 [6] (0) | 2021.01.22 |
|---|---|
| R언어 공부 정리 [5] (0) | 2021.01.21 |
| R언어 공부 정리 [4] (2) | 2021.01.20 |
| R 언어 공부정리 [2] (2) | 2021.01.18 |
| 분석 , 통계시 유용한 R 언어 설치와 기본 공부 정리 (0) | 2021.01.15 |
